PDQ technique: Remediation deployments
Background
We are big fans of PDQ’s products, starting with Deploy many years ago and a few years back adding Inventory so we could move to LAPS integrations for our deployments, among other benefits. Their reliability, simplicity and features are a pleasant surprise, and we’ve been able to use the software to effectively solve problems and make our own lives easier. And the pricing model works really well for our small team.
As I’ve talked to more colleagues about how we use the software, it became obvious that we needed to write up a particular way in which we use these products. Not because our technique is novel or even particularly interesting, as I’m sure most folks are doing something similar with their PDQ environments. But it is a little complex and perhaps not an obvious way to use the products for beginners, who may not realize that PDQ D&I can be used for hands-off, automated deployments or configuration management jobs. We’ve come to call the technique “Remediation Deployments” internally.
Our approach: Remediation Deployments
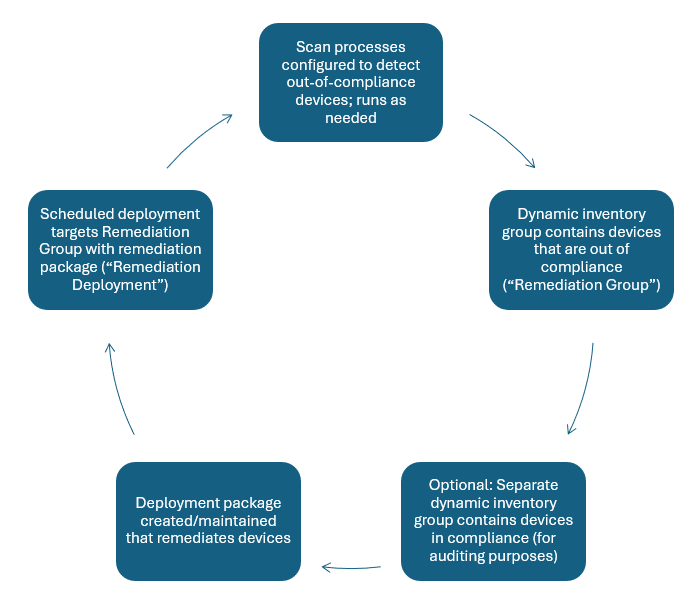
The idea is simple:
-
Create or update your PDQ Inventory Scan Profiles/Scanners to detect systems that are out of compliance with your desired state. Be sure to set Triggers that run often enough to meet your time resolution goals, without running excessively1.
-
Create a PDQ Inventory group that dynamically contains systems that lack the desired state. This is the “Remediation Group”. You may not desire every system in your environment to have this particular state or config, so scope this group to only the audience of potential2 machines you’d want.
-
Optional: Create a related PDQ Inventory group that identifies systems with the state or configuration that you desire. It isn’t strictly necessary to do this, but you may want to depending on the situation, as it could help you with the other work, auditing/reporting, or just for completeness. If you do create a group like this, you can use it to verify that there’s no overlap in membership with your remediation group.
-
Create a PDQ Deploy package that modifies a system, changing its state or configuration to something you desire. This can be as simple as an application install or update, or something less structured/more complicated.
-
Create a recurring Schedule in PDQ Deploy to deploy the package to the Remediation Group; this is the “Remediation Deployment”. Our Remediation Deployments generally run hourly, some more frequently than that.
When working correctly, the machines that don’t have what you want will end up in the Remediation Group, and be remediated by the Remediation Deployment, without you having to do anything. Then they fall out of the Remediation Group as a result of your remediating PDQ Deploy package, PDQ Inventory scans, and group membership rules.
Remediation Deployment example
Let’s walk through the concept with a simple example.
We like to deploy the winlogbeat and other beats clients to select computers in our environment.
1. Create/update your Scan Profiles to account for out-of-compliance systems.
Because it’s not a traditional, registered application, we have to scan for it on the file system. We can build a Remediation Group later based on the absence of these relevant files.
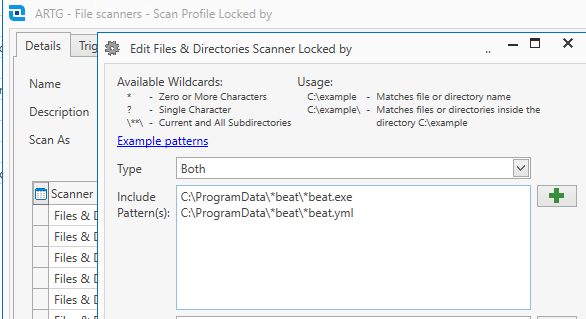
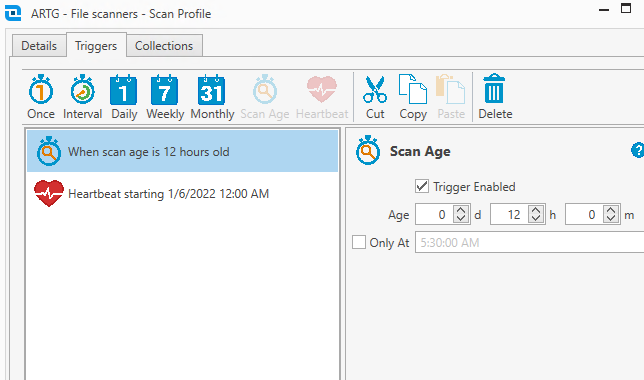
We have our file & directory scans to trigger on what I assume is a relatively aggressive maximum 12hr time cycle, and also have it scan on heartbeat changes.
We’ll do the next two steps in opposite order, principally because I do like having the correlated auditing groups in nearly every instance, and that simplifies creating the Remediation Group in this case.
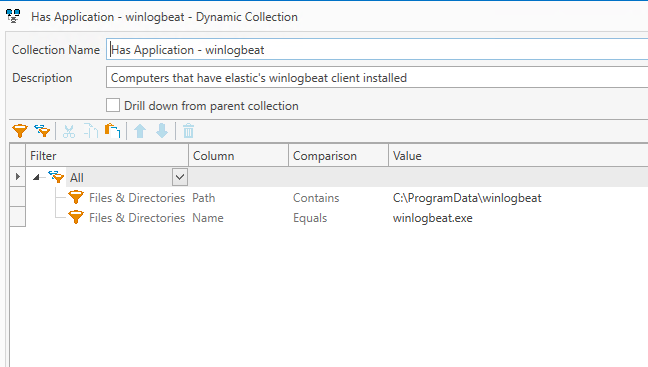
3. Optional: Create a related PDQ Inventory group that identifies systems with the state or configuration that you desire.
This is a simple PDQ Inventory dynamic group that contains the computers that have the state that we want them to have, namely that they have winlogbeat on them.
2. Create a PDQ Inventory group that dynamically contains systems that lack the desired state.
This is our Remedation Group, our dynamic group for identifying computers that lack the configuration we want. We simply referenced the auditing group we just created, but we could have instead built it with the inverse Not All of the File & Directory filters we used previously.
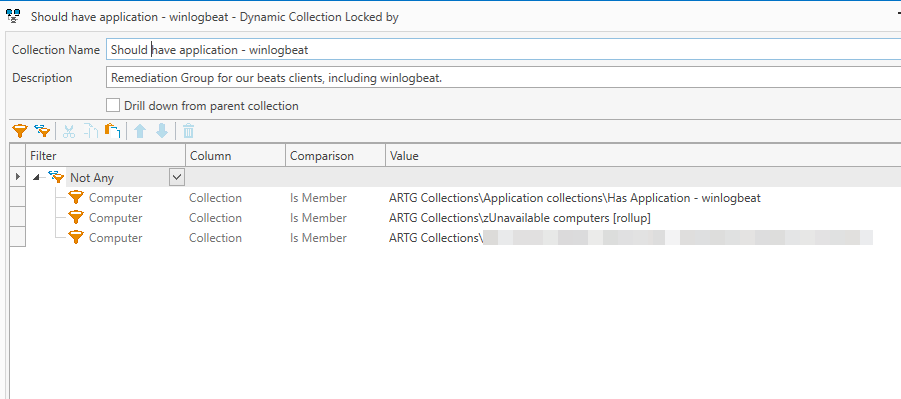
This is a relatively simple group, getting available computer in our environment except for the members of groups listed here, but you can really go nuts with inclusion or exclusion of groups, combined with complicated set math, of anything you can detect with PDQ Inventory.
We like to exclude unavailable computers2 from our deployment groups, to avoid errors and noise.
4. Create a PDQ Deploy package that modifies a system, changing its state or configuration to something you desire.
We had a pre-existing PowerShell script that runs through the installation and configuration of beats clients for Windows machines in our environment, including winlogbeat. So it was relatively easy to just reference that in a PDQ Deploy package.
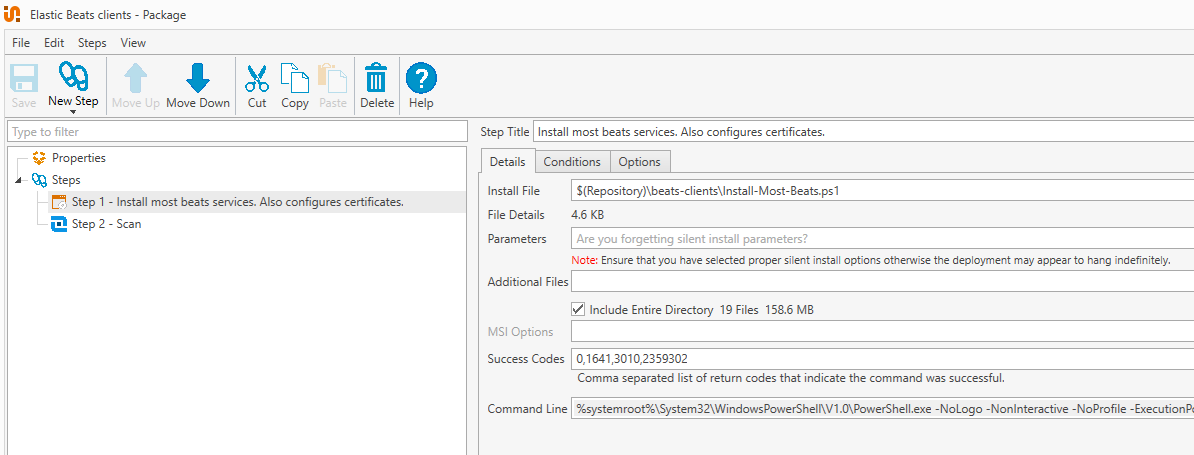
Installing/re-installing is all it means for us to remediate in this case, but your use case could be more involved.
Notice that we also run a PDQ Inventory scan after we run the script. It references the same Scan Profile that we did in Step 1:
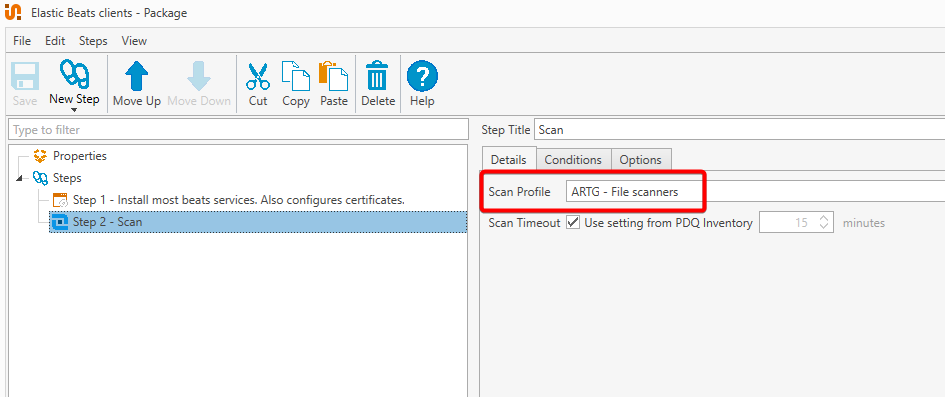
Running the scan after the installation keeps the Remediation Group membership as up-to-date as possible.
5. Create a recurring Schedule in PDQ Deploy to deploy the package to the Remediation Group; this is the “Remediation Deployment”.
This is our Remediation Deployment job, which ties together our Remediation Group and Remediation Deployment with a scheduled trigger.
The job is scheduled to run as often as is reasonable given the particulars, in this example we run once per day:
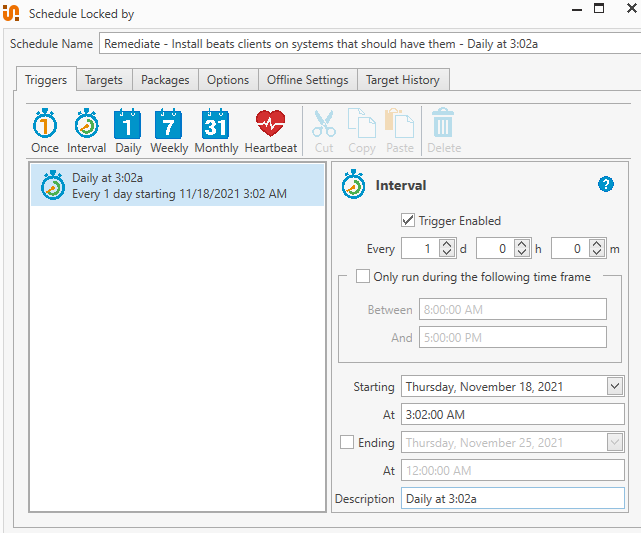
Targets has our Remediation Group:
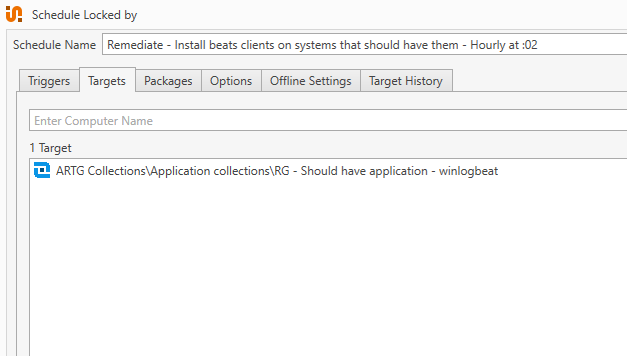
Packages runs our Remediation Deployment:
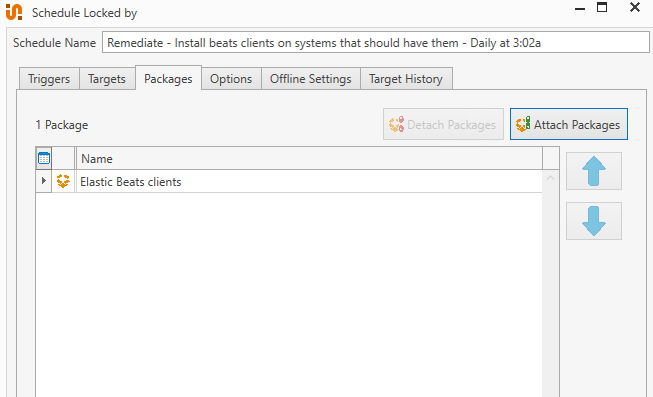
Over time, assuming you have everything running well, new systems or systems that have drifted from configuration will end up in your Remediation Group, and will be remediated by the Remediation Deployment at the triggered time.
PDQ Deploy is clever enough to skip deployments that have 0 members in the targeted group, which is how most of our Remediation Deployments tend to go.
Ideas
You probably have your own ideas of how this could be used in your area, but we use Remediation Deployments for the following in our environment:
- Ensuring our enterprise security software is installed and active site-wide. We do a half-dozen software installs, some post-install software configurations and some security baselining with this approach.
- Ensuring our VMware virtual machines have the latest VMware Tools installed.
- Copying down shared printer drivers for computers that are missing them.
- Targeting computers that failed to successfully complete their weekly maintenance jobs to try again near the end of our maintenance windows. We also have a remediation deployment to force a reboot on machines that require one in our maintenance window as well.
-
We sometimes help this along by running the appropriate PDQ scan after a relevant deployment is done. ↩